Tag: Apache Spark, clustering, machine learning
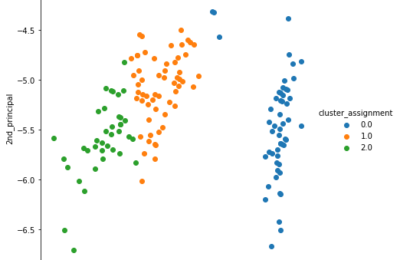
Tutorial: Hierarchical Clustering in Spark with Bisecting K-Means
Prasad KulkarniAug 18, 2021
In the previous article, we covered the standard K-Means Clustering technique on Spark. Read that article here: Tutorial : K-Means Clustering on Spark. In this article,...
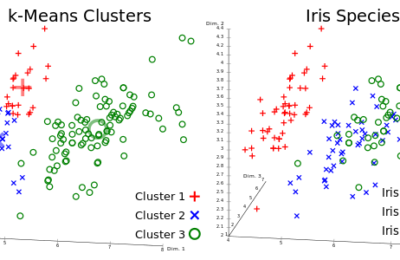
Tutorial : K-Means Clustering on Spark
Prasad KulkarniAug 10, 2021
Analytics is discovering insights using data. Traditionally, statistical and visual techniques dominated the field. But, with advances in Machine Learning and AI,...
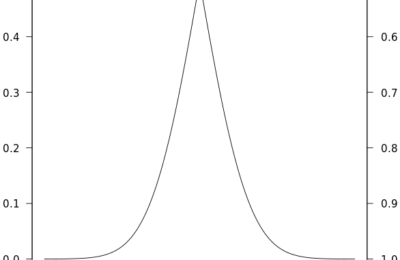
Cumulative Distribution in Azure Databricks using Spark SQL
Prasad KulkarniMay 24, 2020
We can solve every problem in multiple ways. In our previous article, we motivated the need to fit cumulative distributions. Moreover, we demonstrated the same in Azure...
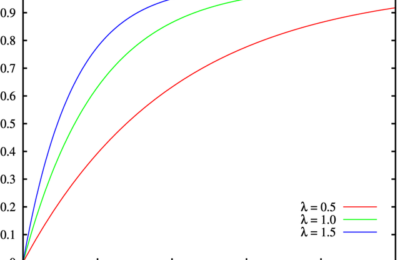
Cumulative Distribution in Azure Databricks
Prasad KulkarniMay 03, 2020
Imagine that you receive a requirement to calculate the aggregations like average on a range of percentiles and quartiles, for a given dataset. There are two ways to...

Databricks Koalas: bridge between pandas and spark
Prasad KulkarniMar 22, 2020
Imagine that you are an ML engineer. You have a massive task of operationalizing a model trained and tested by your Data Scientists. It is working perfectly well for the...

How to read mismatched schema in apache spark
Prasad KulkarniDec 20, 2019
In today’s world, python dominates the data analysis space, while apache-spark rules the big data paradigm. The former contains a plethora of libraries like pandas...

Spark Dataframe performance benefits
Prasad KulkarniMay 07, 2019
Before we move to Spark Dataframes and its benefits, it is imperative to look at the concept of Dataframe. A Dataframe is based on the concept of a statistical table. It...

Azure Databricks tutorial: end to end analytics
Prasad KulkarniMay 02, 2019
Before jumping to the Azure Databricks tutorial, it is good to know the evolution of the Data and AI space. Knowledge production started in ancient Sumerian...