In today’s world, python dominates the data analysis space, while apache-spark rules the big data paradigm. The former contains a plethora of libraries like pandas for data engineering. However, it does not scale with the modern requirements of big data. Here, apache-spark comes to rescue thus creating a formidable combination in the form of pyspark.
Also read: Log Analytics with Python Pandas Explode
Apart from performance and scale, pyspark has rich API for data extraction and manipulation like pandas and other python libraries. Owing to that, we can handle multiple scenarios that arise in the era of the big data world. One such scenario is reading multiple files in a location with an inconsistent schema.
‘Schema-on-read’ in Apache Spark
The reason why big data technologies are gaining traction is due to the data handling strategy called ‘Schema-on-read’. Contrary to the traditional databases, which need to have a rigid schema definition (Schema-on-write) before writing, technologies like Map Reduce and Spark allow us to read data without a rigid schema definition. Let’s take an example to understand this.
We have a file of Injury records of basketball players called InjuryRecord_withoutdate.csv.
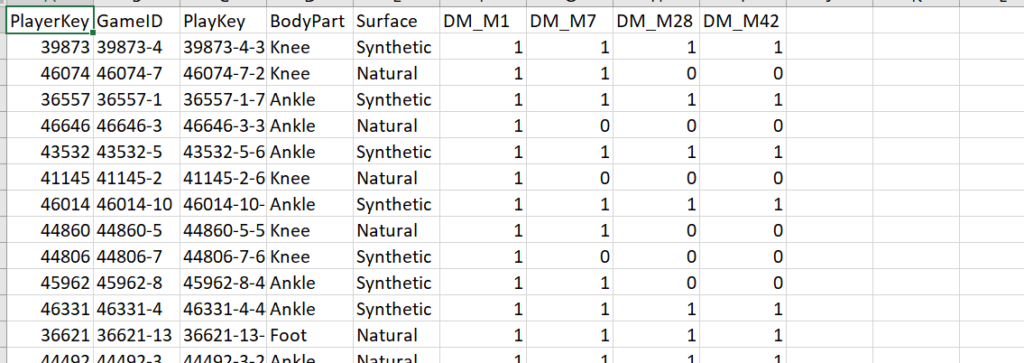
If we wish to load this data into a database table, a table structure needs to be in place. However, to the contrary, in big data technologies like HDFS, Data Lake etc. you can load the file without a schema and can read it directly into compute engines like Spark for processing.
For instance, let’s walk through a code snippet Azure Data bricks(Spark). We have the file InjuryRecord_withoutdate.csv loaded in Databricks File System
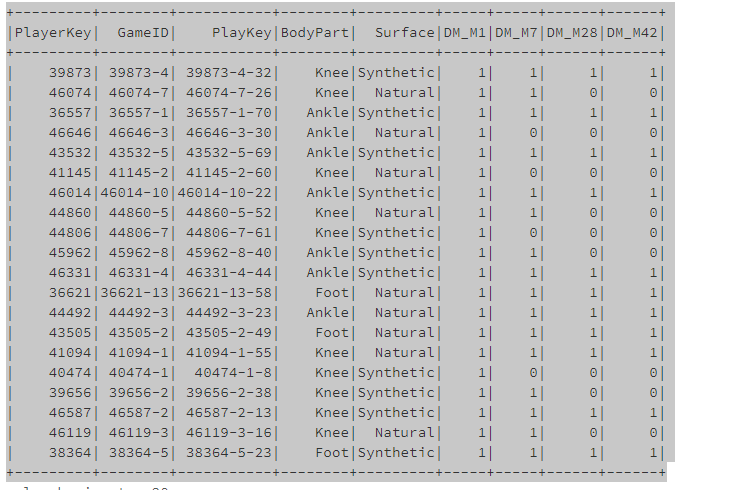
We read the file using the below code snippet. The results of this code follow.
# File location and type
file_location = "/FileStore/tables/InjuryRecord_withoutdate.csv"
file_type = "csv"
# CSV options
infer_schema = "false"
first_row_is_header = "true"
delimiter = ","
# The applied options are for CSV files. For other file types, these will be ignored.
df = spark.read.format(file_type) \
.option("inferSchema", infer_schema) \
.option("header", first_row_is_header) \
.option("sep", delimiter) \
.load(file_location)
df.show()
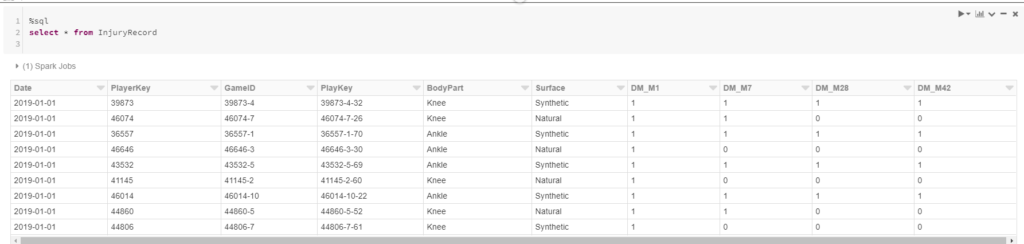
Furthermore, we can create a view on top of this dataframe in order to use SQL API for querying it.
temp_table_name = "InjuryRecord" df.createOrReplaceTempView(temp_table_name)
Place the next query in a different cell.
%sql select * from InjuryRecord
Reading multiple files
Now, in the real world, we won’t be reading a single file, but multiple files. A typical scenario is when a new file is created for a new date for e.g. myfile_20190101.csv, myfile_20190102.csv etc. In our case, we have InjuryRecord.csv and InjuryRecord_withoutdate.csv.
Hence, a little tweaking to the spark.read.format will help. All we have to do is add a trailing * to the file name as shown below.
# File location and type
file_location = "/FileStore/tables/InjuryRecord*.csv"
file_type = "csv" # CSV options
infer_schema = "false"
first_row_is_header = "true"
delimiter = ","
df = spark.read.format(file_type) \
.option("inferSchema", infer_schema) \
.option("header", first_row_is_header) \
.option("sep", delimiter) \
.load(file_location)
Drifting Schema
However, there is a small caveat in the above script. What if the two files viz. myfile_20190101.csv, myfile_20190102.csv etc. have a different schema? This is typical in information systems, owing to varying business requirements, where we will have a set of files with one schema while another set of files with another schema. The technical term is ‘schema drift’. In such a scenario, we would like to retain one set of files while discarding the other.
In our scenario, we will demonstrate schema drift using the two files InjuryRecord.csv and InjuryRecord_withoutdate.csv. The former (shown below) consists of a date column while the latter is devoid of it.
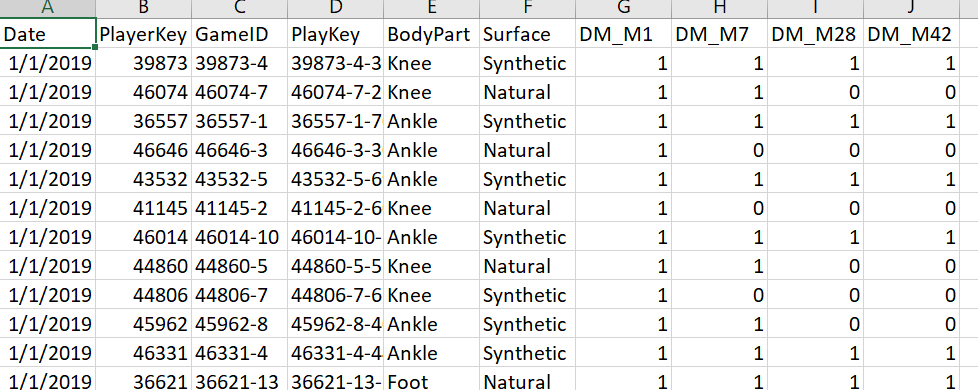
Running the previous script in conjunction with the below SQL statement will give us the following result.
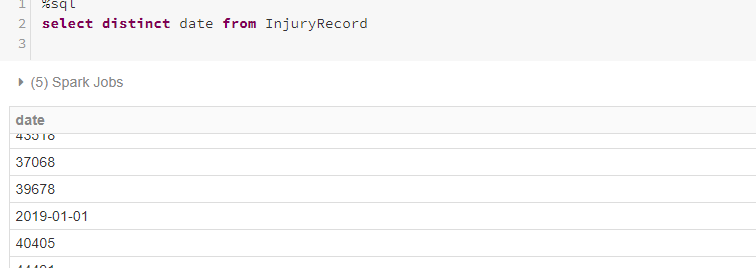
It is evident that the date column of InjuryRecord.csv has gotten messed up with PlayerKey column of InjuryRecord_withoutdate.csv.
Handling Schema drift
Now, how to handle this kind of drifting schema. How do we ensure that we retain schema with the ‘Date’ column and discard the other?
The answer lies his putting a hardbound schema which is similar to putting a table definition. In this case, we would like to retain the schema of InjuryRecord.csv i.e. with the column date. Hence, we will create a schema accordingly. In pyspark, a schema definition can be created as follows.
from pyspark.sql.types import StructType, IntegerType, DateType, StringType, DecimalType
Injury_Record_schema = (StructType().
add("Date", DateType()).
add("PlayerKey", IntegerType()).
add("GameID", StringType()).
add("PlayKey",StringType()).
add("BodyPart",StringType()).
add("Surface",StringType()).
add("DM_M1",IntegerType()).
add("DM_M7",IntegerType()).
add("DM_M28",IntegerType()).
add("DM_M42",IntegerType())
)
Furthermore, we have to use an option called mode and set the value to ‘DROPMALFORMED‘. This is the key option which helps us overcome schema drift. Accordingly, tweak the spark.read.format with the DROPMALFORMED as follows.
# File location and type
file_location = "/FileStore/tables/InjuryRecord*.csv"
file_type = "csv"
# CSV options
infer_schema = "false"
first_row_is_header = "true"
delimiter = ","
# The applied options are for CSV files. For other file types, these will be ignored.
df = spark.read.format(file_type).schema(Injury_Record_schema) \
.option("inferSchema", infer_schema) \
.option("header", first_row_is_header) \
.option("sep", delimiter) \
.option('mode', 'DROPMALFORMED')\
.load(file_location)
We can now see that the second file viz. InjuryRecord_withoutschema has been skipped since only the legit date values appear.
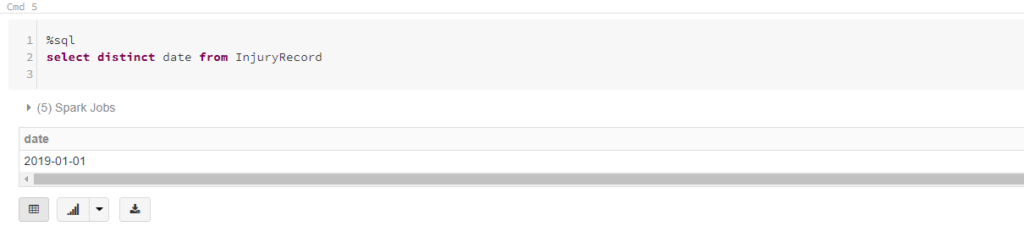
Conclusion
Hope you find this article helpful. Please note that this article is only for information purpose.