Introduction
In the book Modeling Mindsets, Christoph Molnar labels various modeling techniques as a mindset, rather than a toolset. Accordingly, two major modeling mindsets emerge: Statistical Modeling and Machine Learning Modeling.
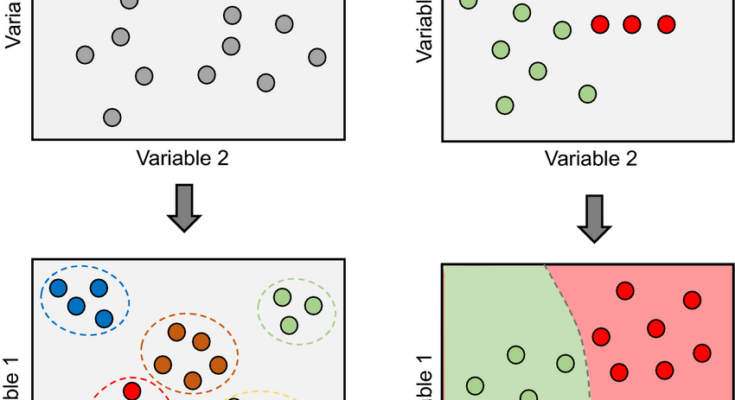
Statistical models are based on the theory of probability. They use historical data to estimate the probability of future events. Statistical models are typically used for prediction and forecasting. Machine learning models are based on the theory of artificial intelligence. They learn from data to make predictions without any prior knowledge.
This brings us to two major classes of Machine Learning Paradigm: Supervised Learning and Unsupervised Learning. Let’s do a brief comparison between Supervised and Unsupervised Learning. Later, we dive deeper into the difference between supervised vs unsupervised learning. Here is a link to learn machine learning online.
Tabular Comparison Between Supervised and Unsupervised Learning
Here is a brief introductory comparison between Supervised learning vs Unsupervised learning:
| Point of Comparison | Supervised Learning | Unsupervised Learning |
| Mindset | Predictive Mindset | Exploratory Mindset |
| Objective | To make predictions | To uncover patterns |
| Data Requirements | Labeled | Unlabeled |
| Evaluation | Robust, coherent, narrow Evaluation methodologies | Broad, flexible, ambiguous evaluation |
| Automation | Can be automated easily | Very hard to automate. |
| Interpretable | Most of the Algorithms are not interpretable, but can be made interpretable | Hard to Interpret |
| Common Tasks | Classification, Regression. | Clustering, Anomaly Detection, Dimensionality Reduction |
| Algorithms | Linear Regression, Logistic Regression, SVM, Decision Tree, Ensembles, Neural Networks, etc. | K-Means, DBSCAN, PCA, Isolation Forest, etc. |
| Applications/Use Cases | Spam Filtering, Customer Churn, Forecasting, Pattern Recognition | Segmentation, Predictive Maintenance, Text Mining, etc. |
Supervised vs Unsupervised Learning: Detailed Comparison
Now, before diving into detailed comparisons of Supervised/Unsupervised learning, let us understand these terms in more details. But before that, let’s review the Machine Learning theory first. A machine learning model or a learning agent learns from experience E, with respect to some class of tasks T, and performance measure P, if its performance in tasks in T, as measured by P, improves with experience E. Now, let’s put Supervised and Unsupervised learning in this framework or definition.
What is supervised learning?
A Supervised Learning Agent has the following characteristics:
Task T: Predicting, Classifying, Forecasting, etc.
Performance Measure P: Predictive Error, Accuracy, etc.
Experience E: Historical, Labeled Data in a Database.
Having said that, Supervised Learning algorithms/agents are trained using labeled data i.e. every instance has the ground truth- a category, label. The algorithm learns to associate the input features with the target or label variable. Mathematically, it can be represented as:
y = f(x) + ε where:
-
yis the output variable -
xis the input variable -
f()is the model function -
εis the error term
Supervised Learning can further be classified as Regression and Classification. In regression, the target variable y is continuous, numerical in nature whereas, in classification it is categorical. An example of Regression is stock price prediction, where the target value i.e. stock prices, can take any value. On the other hand, an example of classification could be image classification i.e. to classify various images amongst cat, dog, etc.
What is unsupervised learning?
An Unsupervised Learning Agent has the following characteristics:
Task T: Identify Patterns
Performance Measure P: Similarity, Separation, Compactness of clusters
Experience E: Historical, Unlabeled Data in a Database.
Note the key difference here. Unlike Supervised Learning, Unsupervised learning does not consist of labeled data. The algorithm is supposed to identify patterns in data and cluster them in groups on its own. Hence, performance evaluation of the algorithm is ambiguous and subjective. Moreover, it cannot be expressed in a close, compact mathematical form easily.
Examples of Unsupervised Learning include Clustering, Anomaly Detection, PCA, etc.
Having said that, let’s compare the two approaches of Machine Learning in more detail.
Mindset in supervised vs unsupervised learning
The mindset behind Supervised Learning is that the best way to do data science is by predicting something. It is an objective driven or goal driven mindset. On the other hand, in unsupervised learning, it is an exploratory or subjective mindset. This mindset is about finding hidden patterns. To learn more about Data Science, here is a data science course.
Objective of supervised vs unsupervised learning
From mindset, we go to the objective. In supervised learning models/agent learn from seen data and predict on unseen data. Mathematically, it can be expressed as an Optimization and Search problem. On the other hand, an Unsupervised Learning model/agent finds hidden patterns in data. Every technique has a different mathematical objective. For instance, K-Means Clustering maximizes separation of clusters whereas, PCA finds directions to preserve maximum variance.
Data Requirements of supervised vs unsupervised learning
With different mindsets and objectives, data requirements are diverse in supervised learning vs unsupervised learning. In the former, labeled data is necessary. While on the other hand, Unsupervised learning does not require labeling.
Evaluation of supervised vs unsupervised learning
Evaluation is measuring the performance of an algorithm. This is the key difference between Supervised and Unsupervised learning. Due to the availability of ground truth or reference, evaluation of supervised learning is much more compact and robust than unsupervised learning. Evaluation measures like Mean Squared Error, Accuracy, Precision, Recall, F1-Score exist for Regression or Classification problems which can evaluate supervised learning algorithms in a precise, objective way.
On the other side evaluation measures do exist in Unsupervised Learning, especially in Clustering like Dunn Index, Silhouette Score, etc. However, cannot be taken at face value and human judgement is required to evaluate them
Common Tasks in supervised vs unsupervised learning
There are some standard tasks T, that can be performed using both Supervised and Unsupervised learning.
With supervised learning, the common tasks Classification and Regression. In Unsupervised Learning, common tasks include Clustering, Dimensionality Reduction, Anomaly Detection, etc.
Algorithms for of supervised and unsupervised learning
To achieve the aforementioned tasks, a laundry list of algorithms are available.
Supervised
For Classification, popular algorithms include decision trees, random forests, support vector machines (SVM), naive Bayes, logistic regression, and deep learning models like convolutional neural networks (CNNs) and recurrent neural networks (RNNs).
Common regression algorithms include Linear Regression, Polynomial Regression, Decision Tree Regression, Random Forest Regression, Support Vector Regression (SVR), Gradient Boosting Regression, Neural Network Regression.
Unsupervised
In unsupervised learning, common clustering algorithms include K-means, Hierarchical clustering, DBSCAN, etc.
Common Anomaly Detection Algorithms include One Class SVM, Isolation Forest, Local Outlier Factor etc.
Applications/Use Cases of supervised and unsupervised learning
All the tasks and algorithms have applications in various domains across industry. Common use cases in Supervised learning include spam filtering, customer churn, forecasting, pattern recognition, etc.
In Unsupervised learning, key use cases include segmentation, fraud detection, text mining, etc.
Other Key Differences Between Supervised and Unsupervised Learning
There are some other key differences between supervised and unsupervised learning.
Automation
Since supervised learning algorithms have robust, objective metrics and ground truth, it is easier to automate the entire ML lifecycle i.e. Training and Deployment. This has given rise to an entire new engineering disciple called as MLOps.
However, it is challenging to automate unsupervised learning, especially training, due to lack of objective measures.
Interpretability
Another key difference between supervised and unsupervised learning is interpretability. Although most of the supervised learning algorithms are not interpretable inherently, a lot of techniques have been developed to make most of them explainable.
Unsupervised learning algorithms on the other hand are very hard to interpret. Although some techniques do exist to make algorithms like Isolation forest interpretable.
Supervised vs Unsupervised Learning: Which is Best for You?
Now, typically, these questions may arise: Which is better supervised or unsupervised learning? When to use supervised vs unsupervised learning?
The answer is it depends! It depends on the use case, availability of data, resources and expertise, etc.
Most of the use case in Industry are Supervised learning, since it is more deployable to make decisions. On the flip side, it requires tedious process and hours of expert working hours to perform labeling. However, techniques like Active Learning are now available to perform labeling in an automated way.
But Unsupervised Learning has its own applications. Typically, it is used for Data Exploration, detect anomalies, dimensionality reduction. However, it is hard to deploy most of them in the real world.
Semi-supervised learning: The best of both worlds
In the real world, it is not always either Supervised or Unsupervised learning. There is a learning paradigm called Semi-Supervised learning, which combines the best of two worlds. So, where is semi-supervised learning typically used?
As we mentioned earlier, getting labeled data is expensive. However, in the real world, datasets may have some labeled data and remaining could be unlabeled. In such cases, a hybrid approach is useful. Typically, in semi-supervised learning, labeled data is used to learn patterns and unlabeled data is used to learn the underlying structure of the data.
For example, in an algorithm called Self-training, it starts by training a model on a small set of labeled data. The model is then used to predict the labels for the unlabeled data. The predicted labels are then added to the labeled data set, and the model is retrained. This process is repeated until the model converges.
Conclusion
In conclusion, we would like to say that both mindsets, i.e., Supervised or Unsupervised learning have their own advantages, disadvantages and applications. They are different starting from mindset, objectives, data requirements, etc. They differ in their evaluation approach, interpretability. Moreover, they find diverse applications in real-world scenarios like forecasting, categorization, anomaly detection, etc.
They can be combined in ways like Semi-Supervised or Active Learning to solve real-world challenges
P.S.
- Adapted from my article on KnowledgeHut.
- Image credit – ResearchGate


