As we usher into the age of AI, Analytics, and Data Science, we have Data-Intensive applications. What do we mean by that? According to Martin Kleppmann, the author of Designing Data-Intensive Applications, they are the applications in which the major challenges are brought in by the amount of data, its complexity, and the speed at which it is changing. In other words, the volume, variety and velocity of data is the major challenge. Sounds familiar? These are the 3V’s of Big Data. This complexity has created a discipline called Data Engineering. Data engineers are responsible for creating and maintaining the data pipelines that enable organizations to collect, store, process, and analyze data. Enroll in this Data Engineer Bootcamp to gain hands-on experience and practical knowledge in the field of data engineering.
The following building blocks comprise a Data Intensive Application:
- Data Storage (Datalakes/Databases)
- Caching for fast retrieval
- Search indexes
- Stream processing
- Batch Processing
Now, to build and maintain these big data systems, organizations need to build effective processes. This is where the process of Data Integration comes in. Having said that, what is Data Integration? Let’s dive into it.
What is Data Integration?
Data Integration is bringing data from different sources into a single, coherent structure. It starts with Data Ingestion, followed by cleansing, transformation and efficient storage. In common parlance, ETL is commonly cited as a Data Integration example. However, later we see that it is one aspect of Data Integration.
Also read: Introduction to SSIS and making it metadata independent
Why is Data Integration Important?
Hence, the key question would be, “Why is data integration important?”
Organizations receive and collect a lot of data. However, most of the time, it lives in silos and serves the operational needs of the individual business units. The Data Integration process aims to unify these disparate data sources into a single unified view, to be used for Business Intelligence or Data mining needs.
Moreover, with AI and Data Science initiatives, easy access to unified organizational data becomes a tactical necessity. Furthermore, business analysts and product managers could discover new potential use cases with easy access to data, thus making effective Data Integration a Strategic necessity. Lastly, a unified data strategy gives enterprise customers a single view of their data.
How Does Data Integration Work?
No data integration project starts without a business need, be it operational, analytical or research needs. Across these requirements, the process is divided into two major components: Data Processing and Data Presentation.
A. Data Processing
The Data processing entails the following steps:
- Data Identification: The first step of the process is the identification of Data Sources. As aforementioned, data lies in various formats across multiple sources. It is key to identify these in alignment with business needs.
- Data Extraction: The next step is data extraction. This needs to happen using reliable and repeatable pipelines.
- Data Transformation: In this step, data is cleansed, massaged, and standardized for business needs. This includes enhancement of data quality and calculations in-lieu with business needs.
- Data Load: It is important that data is loaded/stored efficiently and accessibly in storage like data warehouses or data lakes for business use.
- Data Refresh: With increasing speeds of business transactions, it is important that the data in these information systems stay updated. Moreover, it is necessary that the changes are tracked to maintain lineage.
Having said that, the above steps need not be in order. They may vary in sequence, clubbed together or skipped, based on the design pattern. Two major design patterns emerge in the world of information systems, viz. Batch Processing and Stream Processing.
B. Batch Processing
This design pattern is commonly used when large amounts of data need to be processed. There are two ways to perform batch processing, viz. ETL and ELT.
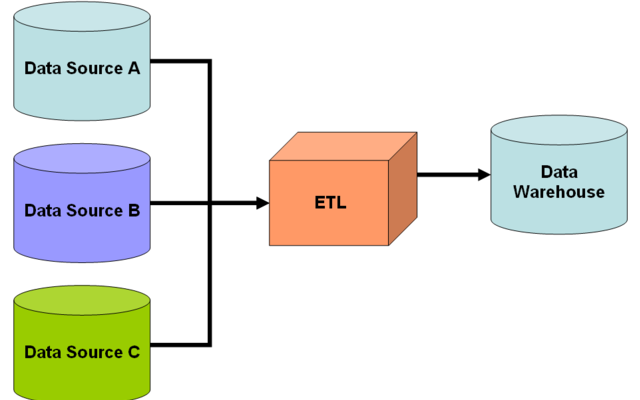
1. ETL:
ETL stands for extract, transform, and load. It is the process of data integration in which data is extracted from disparate sources, transformed to make it suitable for analysis and finally, loaded into a target database, typically a data warehouse.
ETL has existed as data integration in databases since the 1970s, but has gained momentum since data warehouses took center stage in the 90s. It is an essential part of the traditional yet famous Business Intelligence stack. ETL enables the developers to tightly control the transformation process for quality and consistency.
Nonetheless, the ETL data integration paradigm has had certain limitations too. Most ETL workloads in the industry are designed for working with databases, since data warehouses have typically been built on structured data. This made them tightly coupled to the schema, making them metadata dependent. This makes the ETL development process complex and inflexible. While there are ways to circumvent these limitations, there is a lot of maintenance and cost overhead.
2. ELT:
The inflexibility of ETL led to an alternate paradigm called ETL. Often, Data Analysts and Scientists need a certain flexibility to explore data for mining new patterns in data. Data warehouses and ETL pipelines restrict them. Moreover, even if the BI teams decide to cooperate with them, it takes painful cycles of time to make the requisite data available.
Thus, extract, load, and transform provide a good alternative. Moreover, modern storage technologies like Data Lakes enable teams to store practically huge amounts of data in all formats. Thus, Data Analysts and Scientists can explore data at their own pace and convenience, performing calculations and analysis on the fly, as per business needs.
3. Stream Processing/Data Streaming:
It is a type of data processing that involves the continuous processing of data as it is generated. As opposed to batch processing, data is processed in real-time with minimal delay. This is useful while analyzing sensor data, social media feeds, and stock market data, where quick decisions need to be made, and better responsiveness is expected in dynamic conditions.
Together, Batch Processing and Stream processing comprise the Lambda Architecture.
4. Data Presentation:
All the data integration workloads serve the end users. Hence, it is important to make sure that the data is presented in a secure, easy-to-use way. Data presentation was simple in the BI world, owing to the simplicity and homogeneity of data.
However, with massive data lakes containing data in all shapes and sizes, it is very hard for semi/non-technical users to access and analyze data. The answer to this challenge lies in data virtualization.
5. Data Virtualization:
Data Virtualization is a technique in which a logical layer is created on top of physical data to make it meaningful to a business user. This layer can then connect to a variety of tools and applications, including Analytics workloads. Data virtualization leads to improved access, reduced duplication and faster analytics. It is the workhorse of data integration in data mining for modern enterprises.
6. Application Integration:
Apart from building Analytical and AI workloads, information systems can also be used for data sharing. This helps enterprises create a single view of their data for the customer. This is typically performed using APIs, and the process is known as Application Integration. Application Integration enables different applications to communicate and share data with each other in a secure and scalable manner.
Nevertheless, we have discussed the concepts enough. We will now introduce some tools for realizing them.
Data Integration Tools
Let’s take a look at a few Data Integration tools:
- Fivetran: It is a low-code ETL solution with multiple pre-built connectors for widely used data sources. Moreover, request for new connectors is also served by Fivetran engineers.
- Stitch: It is a cloud-first open-source data integration tool owned by Talend. It is used by many businesses for Data Warehousing and Big Data Analytics applications.
- Integrate: This tool has a straightforward UI that reduces the hard work of creating pipelines. Some key capabilities include ELT, CDC, reverse ETL, observability etc.
- Informatica: One of the most popular tools, it is a cloud data integration tool for performing ETL and ELT using thousands of connectors. It can perform very complex transformations.
- Panoply: It is a cloud data platform to sync, store and access your data. It is used in conjunction with other integration tool likes like Stich.
- Talend: Another prominent Data Integration tool that can integrate cloud and on-premises data, with access to strong GUI, templates and a large library of components for building efficient pipelines.
- Boomi: It is a data integration tool that can be used in the cloud, on-premises and hybrid settings. It is a low-code solution.
Data Integration Use Cases
All said and done, what’s the use of Data Integration? While we did touch upon its use cases, let’s take a slightly deeper dive. Following are the use cases of Data Integration:
1. Data Governance
Data governance is the process of data management that deals with lineage tracking and data quality. Efficient Data Integration services have a direct impact on Data Governance since a lot of these workflows need robust and scalable pipelines.
2. Business Intelligence and Data Warehousing
The first step of any BI/Data warehousing project is ETL Data Integration. Hence, good quality data integration is imperative for faster and quality reports.
3. Data Science, ML, AI
No Data Science/ML/AI project is possible without access to sufficient, good-quality data. Hence, Data Integration is an inalienable aspect of these projects, which are of strategic importance to organizations. The best Data Science certification for professionals who want to specialize in data integration could be an important step toward success in this field.
Benefits of Data Integration
Unlike other software products, data initiatives have intangible benefits. Access to good data keeps the decision-makers in touch with the realities of their business. However, if things go south with data, businesses might lose clients, face legal consequences and lose reputation.
Thus, a robust data integration strategy is the growth engine of any organization. Nonetheless, the following are some of the measurable benefits of data integration:
- Improved data quality
- Better decision making
- Enhanced collaboration
- Increased Efficiency
- Cost Savings
Challenges of Data Integration
All said and done, Data Integration has its own fair share of challenges. The first challenge is business buy-in. Individual business units are hard to convince about the potential benefits of Data Integration. It is hard to convince them of the bigger picture since all of them are deeply engrossed in their own KPIs.
The second challenge comes from silos. Even if one breaks through the mindset hurdles, locating and mapping disparate sources is a huge technical and process challenge. Third comes technology and cost bottlenecks. While data integration software has evolved to a great extent, it has cost implications too. Because of limited budgets, and shifting priorities, Data Integration usually suffers.
Lastly comes the adoption challenge. Even though you might convince all the decision-makers, scale all the technical challenges and build an ecosystem. But, if it is hard to use, adoption suffers. Hence, it becomes difficult to justify ROI on such projects.
Data Integration in Modern Business
Fortunately, because of the competitive nature of humankind, Data Integration projects have evolved into a Strategic asset as opposed to a technological liability. Modern businesses are moving towards a model-centric decision-making approach. The business has moved from simple monthly reports to real-time and AI-assisted decision-making. Such shifts have enhanced the need for a robust Data Integration Strategy.
Conclusion
This article hopes to build the first principles behind the exciting, vast and fast-changing field of Data Integration. We covered the need for Data Integration, the skills required, its taxonomy, evolution, opportunities and challenges. One of the skills required in data integration and KnowledgeHut Data Engineer Bootcamp can give more information regarding data science.
We hope this turns out to be informative.
Originally published at https://www.knowledgehut.com.


