
Imagine that you are an ML engineer. You have a massive task of operationalizing a model trained and tested by your Data Scientists. It is working perfectly well for the sample data your Data Engineers gave them. However, there is a catch! They have used pandas dataframe, while you have to productionize the model in a big data environment like Apache Spark. Here begins your nightmare, since pandas API do not scale into a distributed environment like Spark. Hence, either you have to downsample your data (big no) or move to PySpark, the python flavour to spark.
However, PySpark API’s are substantially different from that of pandas. Hence, this entails a learning curve in addition to reinventing the wheel, translating the pandas’ code to pyspark. As a result, a considerable effort goes into the development and testing of the code. Hence, in order to address this Databricks came up with Koalas (I don’t know why the python community is obsessed with animal kingdom)
Introducing Koalas
The primary advantage with Koalas is that you need to write minimal new code while moving from a single machine to a distributed setup like apache spark. In this article, we will go through some basic API’s in Pandas, which when converted to PySpark, get complicated. Further, will build the same code in koalas and see the results for ourselves.
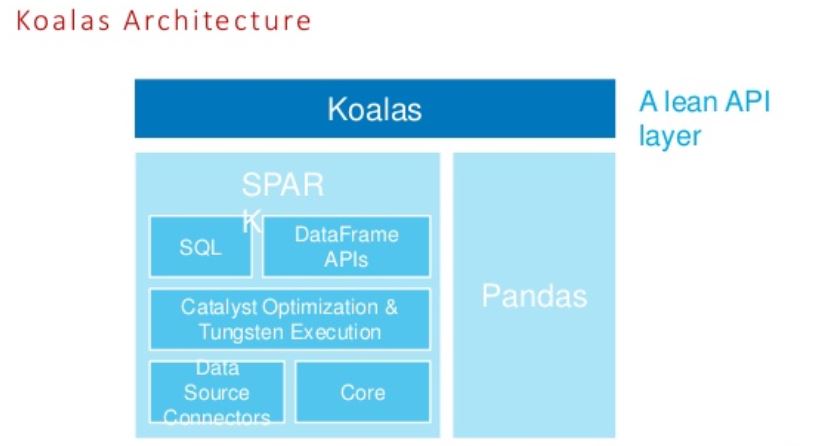
Setup for Koalas
Please note that this article is not against PySpark. I personally love it. However, if you are conversant with pandas, you will find Koalas handy. Nonetheless, firstly some housekeeping stuff. Here we will use Azure Databricks for demonstration. Hence, first, install Koalas on Databricks runtime(5+) using the below command:
dbutils.library.installPyPI("koalas")
dbutils.library.restartPython()
Furthermore, let us read data from dbfs using the below pyspark code snippet. In this example, let us use the Haberman’s dataset for cancer survival.
# File location and type
file_location = "/FileStore/tables/haberman.csv"
file_type = "csv"
# CSV options
infer_schema = "true"
first_row_is_header = "true"
delimiter = ","
# The applied options are for CSV files. For other file types, these will be ignored.
df = spark.read.format(file_type) \
.option("inferSchema", infer_schema) \
.option("header", first_row_is_header) \
.option("sep", delimiter) \
.load(file_location)

Haberman data
Now, the above code is the first point of comparison between pyspark and the remaining two, since reading files in Pandas and Koalas is super easy with read_csv function. For pandas, follow this link to know more about read_csv. Similarly, with koalas, you can follow this link.
However, let’s convert the above Pyspark dataframe into pandas and then subsequently into Koalas.
import databricks.koalas as ks pandas_df = df.toPandas() koalas_df = ks.from_pandas(pandas_df)
Now, since we are ready, with all the three dataframes, let us explore certain API in pandas, koalas and pyspark.
1. Counts by values
A classic example in data analysis is getting the distribution of a categorical variable; typically occurs in classification to measure the skewness of a particular class. In Pandas, we use a simple function i.e. value counts. For instance, in Haberman’s cancer survival dataset, the column ‘status’ is the label. Let’s find the distribution of this column:
Pandas:
pandas_df['status'].value_counts()
Koalas:
koalas_df['status'].value_counts()
PySpark:
df.groupby('status').count().show()
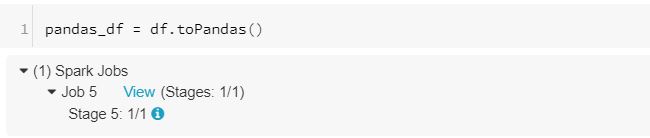
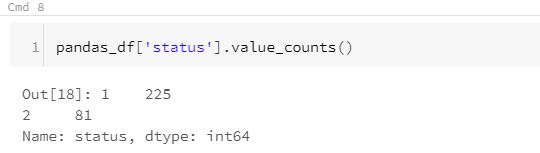
It is evident from a simple statement that moving from pandas to pyspark is a tedious process. Hence, Koalas comes in handy. However, one might wonder what’s the difference between Pandas and Koalas? The answer lies in execution. While pandas API executes on a single node, koalas API does the same in a distributed fashion(similar to pyspark API). The below screenshot of the execution should explain the same.
Pandas execution
Koalas execution
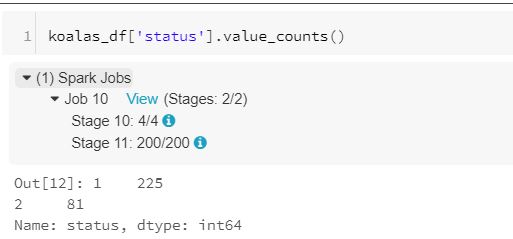
The difference is clearly evident. Koalas run in multiple jobs, while pandas run in a single job. For more information click the tooltip while reproducing this experiment.
2. Calculated/Derived column
Next, let us create calculated columns with all the three API. In Haberman’s dataset, we have two columns viz. year and age. For the demo, we will calculate the birth year which is approximately the difference between year and age.
Pandas:
pandas_df['birthYear']= pandas_df['year']-pandas_df['age']
Koalas:
koalas_df['birthYear']= koalas_df['year']-koalas_df['age']
However, it is significantly different in pyspark.
Pyspark:
df.withColumn("birthYear",df.year-df.age )
3. One hot encoding
Let us see a slightly complicated example i.e. one-hot encoding. This technique is used to create a set of numerical features from a categorical variable. In this example of Haberman’s data, status is a categorical variable consisting of values [1,2]. Hence every row of the column status will be converted to two columns i.e. status_1, status_2 with corresponding values [1,0], [0,1].
In pandas and koalas, it is a one-line code.
Pandas:
import pandas as pd pd.get_dummies(data=pandas_df, columns=["status"])
Koalas:
ks.get_dummies(data=koalas_df, columns=["status"])
However, when you try to implement in pyspark, it is very tedious and the output is not very intuitive since it drops the last category by default. I will leave you with a code snippet for your reference.
Pyspark:
from pyspark.ml.feature import StringIndexer,OneHotEncoderEstimator Indexer = StringIndexer(inputCol="status", outputCol="statusIdx") df_one_hot_idx = Indexer.fit(df).transform(df) encoder = OneHotEncoderEstimator(inputCols=["statusIdx"], outputCols=["statusVec"]) model = encoder.fit(df_one_hot_idx) df_one_hot_encoded = model.transform(df_one_hot_idx) df_one_hot_encoded.show()
Conclusion
These three are amongst the most basic API used in Data Science and ML Engineering. Imagine moving all such code snippets from Pandas to Pyspark! Isn’t it enough to elucidate the importance of Koalas?
Also read: Log Analytics with Python Pandas Explode

