Introduction
For a successful Machine Learning or Data Science practice, the following elements are key:
- Business Case
- Quality Data
- Skilled Teams
- Technology
- Risk Management
One of them is Quality Data. With the rise of Data-Centric AI, good quality data is necessary for an organization’s Data Science effort. However, before enhancing Data Quality, it is necessary to diagnose quality issues and communicate them to the product owners, data owners, and all relevant stakeholders.
Data Quality Metrics
But how do we measure quality? You may argue that quality is subjective. However, there are certain metrics that can quantify data quality as objectively as possible. Here are a few of them:
Completeness : The amount of data (cells) that is present.
Uniqueness : The amount of deduplication.
Validity : Data adheres to a required format.
Accuracy : Data accurately reflects the object described.
Let’s dive a bit into these.
Ideally, in a data table/object, all the fields and cells must be present. The amount of non-missing data i.e. Non NULL and Non-Blank values gives us the Completeness of data. Incomplete or missing data is a major concern for Analytics/Data Science, because it increases the degrees of uncertainty. But, that is not enough. A dataset should not comprise duplicates, since they can bias your model(s). Hence, measuring Uniqueness is essential. Furthermore, the data should adhere to required formats i.e. it must posses Validity. An example could be the email field, where the values adhere to a particular format. This brings us to Accuracy i.e. the data in the system must represent the reality. For instance, an address field must contain a real address or the amount of sales must be a realistic number.
Please note that these are not exhaustive metrics. Other examples could be consistency, timeliness, etc. Moreover, not all of them apply to every column in a table. For instance, Validity applies to fields like email. Accuracy may apply to fields like address or any numerical columns. To arrive at a single metric from such metrics, you may use an appropriate aggregation strategy.
Tools and Techniques
Although implementation of the above ideas may vary from an organization to organization, we may offer some guidance to get started. As an example, we will use a simple flow in Microsoft Azure to monitor data quality.
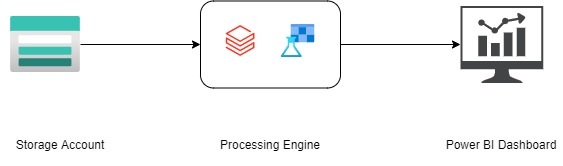
Data from a storage account is processed using tools like Databricks and Azure Machine Learning to calculate the quality metrics. And, the results are displayed in a Power BI Dashboard.
So, why do we need advanced tools like Azure Machine Learning or Azure Databricks? Won’t simpler tools work? There are certain metrics which can be calculated with rules. For instance, Completeness could be straightforward. Validity could be calculated with Regular Expressions. However, Uniqueness and Accuracy aren’t straightforward. Let’s take them one by one.
As aforementioned, Uniqueness is the amount of deduplication. From the definition, it may look straight forward. However, in the real world, duplicates aren’t exact copies. There is some amount of fuzziness. Hence, it becomes practically infeasible to build a rule based system. Thus, advanced techniques like Active Machine Learning can be applied.
Furthermore, Accuracy is the amount of data that reflects the real world. However, the real world is full of uncertainty. Especially with numerical data, you cannot put a hard bound. Hence, techniques like Anomaly Detection come handy.
Conclusion
Please note that the above mentioned quality metrics are not exhaustive. Moreover, definitions may vary. It is up to the Data Science teams to design and define appropriate quality metrics. Moreover, the tools and techniques are for information. They may vary for a scenario. Our aim is not to provide a working solution, but to introduce ideas.
Also, here are a couple of good reads on data quality by Uber and Amazon.