Before we move to Spark Dataframes and its benefits, it is imperative to look at the concept of Dataframe. A Dataframe is based on the concept of a statistical table. It is a data structure comprising rows (cases/tuples) and columns (measurements). A row is a single observation of multiple variables and it can comprise heterogeneous data types. However, a column needs to be homogeneous. Additionally, a dataframe contains some metadata like row names and column names.
Dataframes have a wide variety of applications in data analysis. However, there are two primary benefits:
- They support a wide variety of API for slicing and dicing of data, filtering out rows, normalizing the data, create new columns, aggregations, etc.
- They provide a way to manage the integrity constraints of the incoming data. This is significant because raw statistical data is usually messy. Common examples of messy data are data type mismatch and missing values. Dataframes implement type enforcement for the former, while the latter can be dealt with cleansing API.
Besides the above benefits, Dataframes are a boon to developers and programmers entering the realm of big data from the relational world, since it gives a SQL experience to data. For more on Dataframes, refer to this link: What is a Data Frame?
Pandas Dataframe
Dataframes have been implemented in multiple languages like Python, R, Julia, F#, octave etc. Amongst them, Python’s pandas Data frames have taken precedence. However, I strongly recommend you to explore other languages like R and their Data frames. Before we compare the performance benefits of spark dataframe over pandas, let’s take the scenario which I encountered recently. I had a client who wanted to write dataframe data to an Azure SQL Database from Azure Machine Learning services.
a. Creating ODBC connection and reading the source in a dataframe
Firstly, let’s read some data from an Azure SQL database table named creditdata into a pandas dataframe using ODBC connection:
import pyodbc
import pandas as pd
server = '<myserver>'
database = '<mydatabase>'
username = '<myusername>'
password = '<my password>'
driver= '{ODBC Driver 13 for SQL Server}'
cnxn = pyodbc.connect('DRIVER='+driver+';SERVER='+server+';PORT=1433;DATABASE='+database+';UID='+username+';PWD='+ password)
query = "SELECT * FROM [dbo].[creditdata]"
df = pd.read_sql(query, cnxn)
b. Writing the read dataframe back to Azure SQL database
Now let us write back the dataframe df into another table named creditdata_test2 using SQL Alchemy:
import sqlalchemy
import urllib.parse as ul
params = ul.quote_plus("DRIVER={ODBC Driver 13 for SQL Server};SERVER= <myserver>;DATABASE= <mydatabase>;UID= <myusername>;PWD= <my password> ")
engine = sqlalchemy.create_engine("mssql+pyodbc:///?odbc_connect=%s" % params)
df.to_sql("creditdata_test2 ", engine, if_exists = 'replace')
c. Reviewing SQLAlchemy performance
When we run the code with SQL Alchemy, which by the way is faster than using a cursor, the results are:
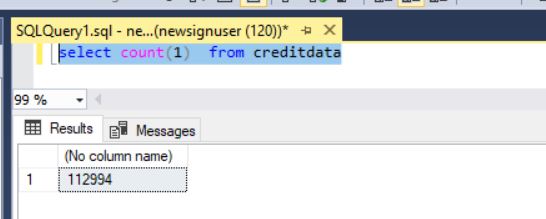
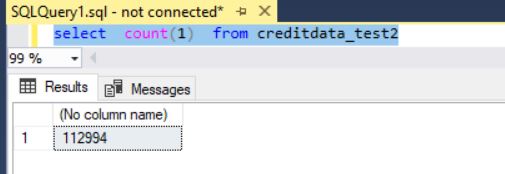
The total number of records in creditdata i.e. the original table is 112994.
When the number of records transferred at 12:45:20 was measured, we had 124 rows.
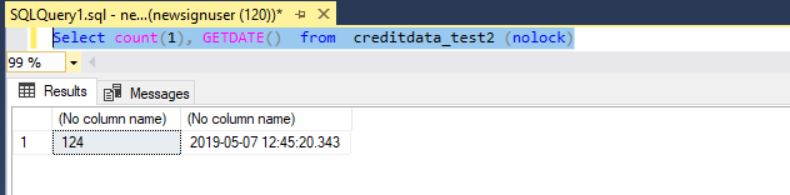
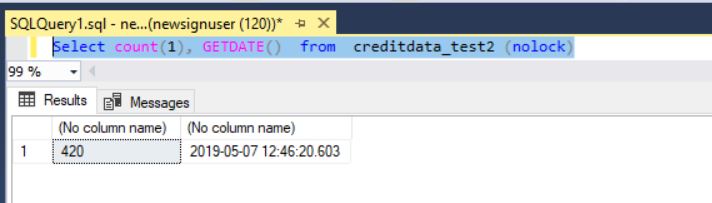
One minute later, at 12:46:20, only 420 rows were transferred!
Spark Dataframe
Now, to demonstrate the performance benefits of the spark dataframe, we will use Azure Databricks. For more on Azure Databricks: Azure Databricks tutorial: end to end analytics.
The primary advantage of Spark is its multi-language support. Let’s take a similar scenario, where the data is being read from Azure SQL Database into a spark dataframe, transformed using Scala and persisted into another table in the same Azure SQL database. Here is a step by step guide:
a. Creating a JDBC connection
Firstly, we redact credentials for Azure SQL Database from key vault secrets. Secrets are a key vault feature for storing sensitive credential information. In Databricks, it is achieved using the key-vault backed secret scope. Here is the comprehensive documentation for setting up the same.
val jdbcUsername = dbutils.secrets.get(scope = "AvroScope", key = "username") val jdbcPassword = dbutils.secrets.get(scope = "AvroScope", key = "password")
Now we create a JDBC connection using the below code:
val jdbcHostname = "<Your Server name>"
val jdbcPort = 1433
val jdbcDatabase = "<Your Database Name>"
// Create the JDBC URL without passing in the user and password parameters.
val jdbcUrl = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase}"
// Create a Properties() object to hold the parameters.
import java.util.Properties
val connectionProperties = new Properties()
connectionProperties.put("user", s"${jdbcUsername}")
connectionProperties.put("password", s"${jdbcPassword}")
b. Reading data into spark dataframe
Once the connection string is formed, a simple spark.read.jdbc function helps us read the data from the table source table creditdata.
val df = spark.read.jdbc(url=jdbcUrl,table="creditdata", properties=connectionProperties)
c. Writing the spark dataframe to Azure SQL database
Finally, we write the data read into df, as is in the Azure SQL database table creditdata_test2.
df.write.mode("Overwrite").jdbc(jdbcUrl, "creditdata_test2", connectionProperties)
d. Reviewing spark dataframe performance
Below snapshot shows that all the 112994 rows in creditdata were written in creditdata_test2 in a time frame of 2.13 minutes!

We have all the data!
Conclusion
This article is not meant to deride python’s pandas dataframe. I personally love pandas with its rich API for data exploration and manipulation. However, it has its own limitation with row by row insert. This is overcome by spark dataframe in its native scala language. Please note that I am not commenting on the famous PySpark and R data frames. I encourage the readers to try them as well.
Disclaimer: The articles and code snippets on data4v are for general information only. We make no representations or warranties of any kind, express or implied, about the completeness, accuracy, reliability, suitability or availability regarding the website or the information, products, services, or related graphics contained on the website for any purpose.