Data Science has a come a long way. From Jupyter notebooks on a Data Scientists’ laptops, we have moved to complex ML workflows running in cloud infrastructure. Speaking of cloud, all the major cloud providers have created platforms to build complex ML applications. Microsoft Azure has two main platforms viz. Azure Machine Learning and Azure Databricks. Moreover, newer roles like Machine Learning Engineer and MLOps engineer have emerged. Hence, it is necessary to upskill people in these technologies. DP-100 is a great certification to do so. In this article, we will not only give details of the syllabus. A lot of resources do so. We will give you the larger strategic picture behind it.
An organization starts its Data Science and Machine Learning journey with initial business and exploration. This is followed by experimentation. Furthermore, ML modeling and evaluation are performed. However, this is the tip of the iceberg. More challenges emerge as a team operationalizes models. This brings us to MLOps, the counterpart to DevOps in the world of Machine Learning. Following are the requirements of MLOps:
- Orchestrated Experiments
- Artifact versioning
- Continuous Training
- Continuous Inferencing
- Model Monitoring
- Responsible AI practices.
- CI/CD from the DevOps world.
The first stage of AI maturity of an organization is the ability to build models. Second stage of AI maturity is the ability to organize and automate Experimentation, Training, Deployment, and Inferencing. The last stage of maturity is the ability to bring Continuous Integration and Continuous Deployment, famously called CI/CD.
This certification viz. DP-100 mainly focuses on building the skills for the second stage of AI maturity. Hence, it is apt for professionals who would like to make a career in ML Engineering. However, the primary focus of this certification is on Azure Machine Learning.
Azure Machine Learning
It starts with a high-level overview of Azure Machine Learning. AML is a cloud service to speed up and manage ML Lifecycle. It is a tool that can be effectively used by Citizen Data Scientists and Professional ones alike. Hence, it starts with UI tools like Azure Machine Learning Designer and Automated Machine Learning (Auto ML). These easy-to-use UI based tools which can be used by Citizen Data Scientists to perform rapid prototyping. While Azure ML is a drag-and-drop service, Auto ML is configurable. You can read our article on Azure ML Designer here. To learn more about Azure Machine Learning Designer and Auto ML, refer this.
While visual tools are easy and intuitive, there is a little control that can be exercised over them. However, seasoned Data Scientists and Machine Learning Engineers would like to have more control over their ML workflows. They would like to create orchestrated experiments, build workflows, and apply responsible AI practices with the tools and libraries of their choice. And Azure Machine Learning won’t disappoint them. It provides them with control over various assets through the Azure ML SDK. But, before going to the SDK, let’s look at the assets. Here is the high level architecture from Microsoft:
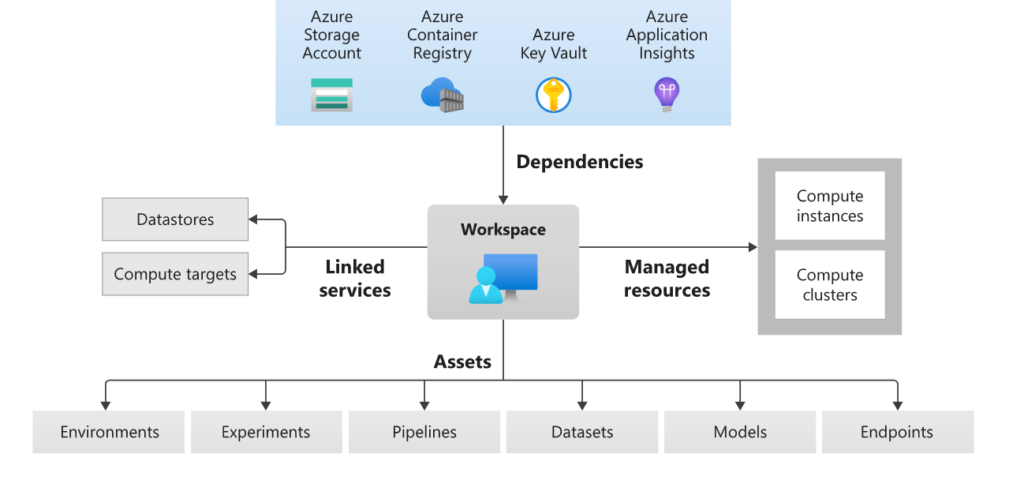
Dependencies
When an Azure ML Workspace is created, four dependencies are necessary, viz. Storage Account, Container Registry, Key Vault and Application Insights. The creator can use existing services or AML creates default versions of these.
Managed Resources
Furthermore, Azure Machine Learning has managed resources like Compute Instances and Compute Clusters. While Compute Instances are used for dev/test purposes, Compute Clusters can be used for Model Training and Batch Inferencing in staging/production.
Linked services
Apart from managed compute resources, users can bring their own compute, like Azure Databricks or HDInsight, that can be accessed via linked services. Besides, datastores like Azure Data Lake and Azure SQL DB can be accessed via linked services.
Assets
Majority of the focus in DP-100 goes to Assets and the SDK for it. To install and use Azure ML SDK, use the following command:
pip install azureml-core import azureml.core print(azureml.core.VERSION)
Experiments
The journey starts with Experiments. An experiment encapsulates any part of the Data Science life cycle, like EDA, Model Training, Deployment, etc. It’s a named process in Azure Machine Learning that can be performed multiple times. Each iteration of the experiment is called a run, which is logged under the same experiment. This section deals with the method to run ML Model Training as an experiment.
Datastores and Datasets
From experiments, we move on to Datastores and Datasets. As aforementioned, Datastores are the linked services to cloud data sources. Datastores are the abstractions in Azure Machine Learning for cloud data sources like Azure Data Lake, Azure SQL Database, etc. Moreover, there are some built-in data stores in the Azure Machine Learning. Datasets, on the other hand are the data objects from the datastores. They are like a view on top of the data present in these stores.
Environments and Computes
Further, we move on to Environments and Computes. An Environment is a setting in which a code runs. Hence, an environment file comprises the dependencies needed to run the code. This is a necessary step since the compute cluster may not have the packages installed. This brings us to Computes. Azure Machine Learning supports four varieties of compute:
- Compute Instances : For Dev/Test purpose.
- Compute Clusters : To scale training and Batch Inferencing
- Inference Clusters : For Real Time Inferencing
- Attached Clusters : External compute like Databricks
Pipelines
All the above combine to build Pipelines. Simply put, a Machine Learning Pipeline is a workflow to automate the parts or the whole of Machine Learning Lifecycle. Further, ML pipelines are of two types viz. Training Pipeline and Inferencing Pipeline. The next two sections of DP-100 deals with Training Pipelines and Inferencing Pipelines. Inferencing pipelines are of two types viz. Real Time Inferencing and Batch Inferencing.
Hyperparameter Tuning and Auto ML
After ML workflows comes Hyperparameter Tuning in Azure Machine Learning, which can be performed by a class called HyperDrive in Azure ML SDK. Moreover, Auto ML makes a comeback in this section, however, as SDK. While Hyperdrive can deal with one ML algorithm at a time, AutoML works with multiple models.
Responsible AI
In this section of DP-100, we learn about responsible AI triad in Azure ML. The RAI triad comprises Privacy, Interpretability and Fairness. To safeguard privacy of user data while not compromising of statistical value is a challenge. However, this can be addressed with the help of Differential Privacy. Read more about it here.
Next in line comes Interpretability. It is the ability to interpret the association between the input and output. We have covered Interpretability in Azure Machine Learning in this article.
Lastly, we deal with fairness. Machine Learning models can be biased against certain groups. Hence, it is imperative to detect and mitigate them.
Model Monitoring
Once the ML workflow is built and deployed, it is necessary to monitor them in production for two types of challenges; Engineering and Scientific. The former is about monitoring the health of the deployed ML Model. It entails system metrics like server load, CPU usage, etc. These insights are stored and monitored via a service called the Application Insights.
However, ML models bring in another set of challenges. Data is the backbone of ML workflow. But data changes pattern. This change is called Drift. To know more about drift, read this.
Azure ML security
Lastly, in the modern digital world, security is of paramount importance. Hence, DP-100 has an exclusive section on Azure Machine Learning security. Read more about it here.
Azure Databricks
While DP-100 focuses on Azure Machine Learning largely, don’t forget Azure Databricks. Besides, it is a powerful data science platform. Hence, it is good to learn it.
Nonetheless, Azure Databricks has similar concepts like Experiments, Datasets, Pipelines, Hyperparameter tuning, etc. This allows Data Scientists and Machine Learning engineers to have a variety of options. To know more, refer to this.
Final Tips for DP-100 exam
We will leave you with certain tips for the DP-100 exam:
- Start your journey with Machine Learning basics.
- Do not ignore Azure Databricks
- Do not ignore AML security
- Don’t ignore visual tools like Designer and Auto ML
- Lastly, try to build some real pipelines using the concepts mentioned above.
All the best!