MLOps is a new, exciting field. With excitement comes uncertainty and with uncertainty, debates emerge. And healthy debates are good for growing the knowledge base of a team. Recently, one such debate erupted. It was about a key question i.e. in which phase of MLOps should model registration happen? For starters, MLOps is divided into two key phases i.e. Experimentation/Training and Serving/Monitoring. For more details, refer to our article on Machine Learning System Design. Having said that, to answer the question, we need to first understand what Model Registration means. For the same, it’s imperative to understand Model Management.
Model Management
With the growing complexities of Machine Learning applications, it is necessary to maintain multiple models in production. Without efficient model management practices, it could be a logistical nightmare for the MLOps teams. Model Management includes ML Metadata Tracking and Model Governance. In ML Metadata Tracking, the artifacts produced by ML workflows are stored, versioned and tracked. For models, the following metadata matters:
- Statistics
- Hyperparameters
- Evaluation metrics or custom artifacts
Model Governance includes storing, evaluating, and versioning ML Models. It also includes the release processes and monitoring. To enable these actions, ML platforms have come up with a centralized repository called Model Registry. And registering the model with this registry is Model Registration. If you want to go through some examples of model registration, read our articles on Azure ML Training Pipelines and Azure ML with Azure Databricks.
In Azure Machine Learning, this is what a registered model looks like:
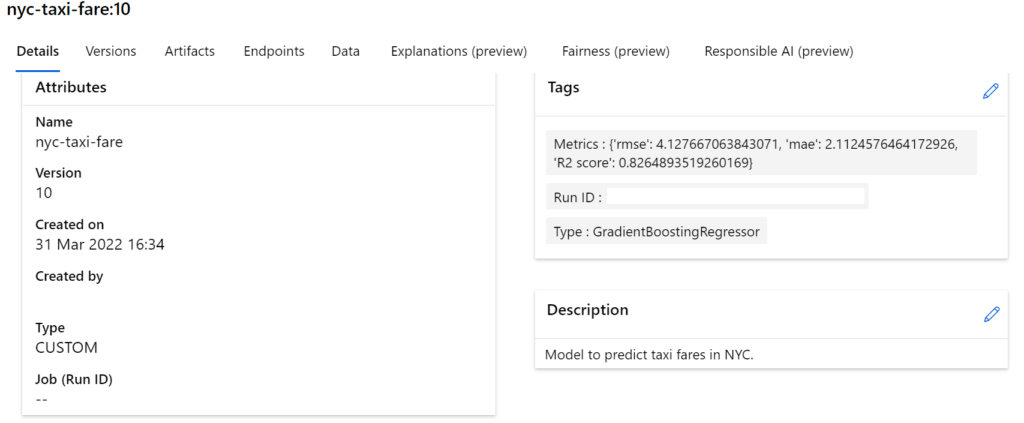
Reading the above two articles, one may conclude that model registration should happen in the training workflow. And it isn’t the wrong answer. After all, a registered model should be associated with the corresponding training run. In the above image, we can see the run_id under the Tags. With multiple models and their versions, it becomes easy to track them if models are associated with their training run and required hyperparameters.
However, it isn’t the only right answer. Model Registration could happen in the deployment phase as well. This brings us to the larger question of environment organization (Dev, QA, Production etc.) for ML projects. There could be various ways to organize environments as detailed in this Microsoft documentation. But, for this article, we will stick to two of them.
Single environment workspace deployment
In this mode, the ML workspace deployment happens in only one environment viz. Development environment, while the model deployment and serving happen in higher environments. To put it simply, the first phase i.e. the training phase is built in the development environment.
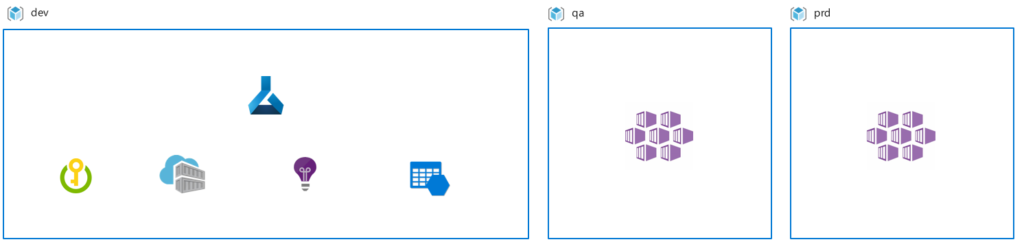
The assumption here is that all the required data is available in the lower environment. This is a feasible solution when the team training the model and the one deploying/consuming it are different in terms of function and purpose.
Multiple environment workspace deployments
Another common mode of organizing ML workspaces is the multi-environment setup. In this mode, a team creates the ML workspace in every environment. Both the training and deployment workflows are (re) created in every environment.

This is a good candidate when partial data is available in non-prod environments for ml development and testing purposes. Moreover, it is good for standard SDLC practices, where every phase of the ML lifecycle goes through thorough QA practices. This is suitable when the entire ML workflow and infrastructure are under one team.
Back to Model Registration…
Having said that, let’s come back to a key question: Where should model registration happen? Is it the training pipeline or the deployment one? It would be ideal to perform it in the training phase if the team uses Multiple environment workspace deployments. This will ensure an association between the training run and the registered model. Please read the aforementioned articles for the same. For example, model registration can happen with a simple API in Azure Machine Learning:
model_name = 'california-housing-prices'
model_description = 'Model to predict housing prices in California.'
model_tags = {"Type": "GradientBoostingRegressor", "Run ID": aml_run.id, "Metrics": aml_run.get_metrics()}
registered_model = Model.register(model_path=model_file_path, #Path to the saved model file
model_name=model_name, tags=model_tags, description=model_description, workspace=ws)
On the other hand, it is practical to perform Model Registration in the Deployment phase, if the team chooses the Single Environment workspace deployment. This way, the team can perform model management, even though they don’t reproduce the training pipelines across environments.
Conclusion
With advances in MLOps, paradigms are fast changing. Hence, there are no fixed answers to these debates. Although there are best practices, they are subject to change with evolving scenarios.


