
A survey said that only one of eight Machine Learning models gets to production. This usually happens because of bad problem definition. We have dealt with that topic in our article: Nuances of Defining the Goal in Machine Learning Life Cycle. This article will discuss the next part, i.e. the Machine Learning Deployment strategies and patterns. But before that, let’s talk a bit about common deployment scenarios and degrees of automation.
Machine Learning Deployment scenarios
There are two scenarios in which ML deployment happens:
- New product/capability: A new product offering with ML embedded into it.
- Existing system upgrades: An existing model update.
Degrees of Automation
It is important to understand the degrees of automation employed while bringing a Machine Learning model as a feature. The below diagram summarizes all the degrees of automation:

This diagram lays out the journey of automation. First, we identify a manual task to automate. After developing the AI/ML model, we deploy it to shadow the human. This helps us gauge its performance, causing no disruption. Once satisfied, we either allow AI to assist/augment the humans or we automate the process partially. In partial automation, human beings review predictions with low confidence levels. The highest level of automation comes in low criticality domains like Internet applications where the cost of the wrong prediction is low.
Machine Learning Deployment Strategies
Let’s delve into some of the most common Machine Learning Deployment strategies or patterns.
Single deployment
This is the simplest deployment strategy. It entails either deploying a new model for the first time or replacing an existing one. However, this is the riskiest strategy since any bug in the model can affect users.
Silent deployment/Shadow mode
As opposed to Single-mode, this mode deploys a new model, keeping the old one intact. Both the versions run in parallel. However, the user isn’t exposed to the new model immediately. We log the predictions made by it to identify any bugs before switching the users to the new model. The advantage of this pattern is that we get sufficient time to evaluate the new model. On the downside, it consumes a lot of resources since every datapoint/feature set is passed to two models.
A variant of silent deployment is the shadow mode. It means that the ML model shadows the human operator for some time before using it for partial/full automation.
Canary deployment
Another disadvantage of silent deployment is that, in many use cases, it is not possible to evaluate the model without exposing it to users; especially in internet applications. Canary deployment addresses this disadvantage. In this strategy, we expose a section of users to the new model or the recent version of the model, while we score most of the users on the older one. The new version acts as a beta version.
A disadvantage of this strategy is that you have to manage multiple versions of the model in your production environment.
Blue-Green Deployment
In this strategy, we maintain two nearly identical production environments. The current environment is a blue environment, while we call the new candidate environment the green environment.
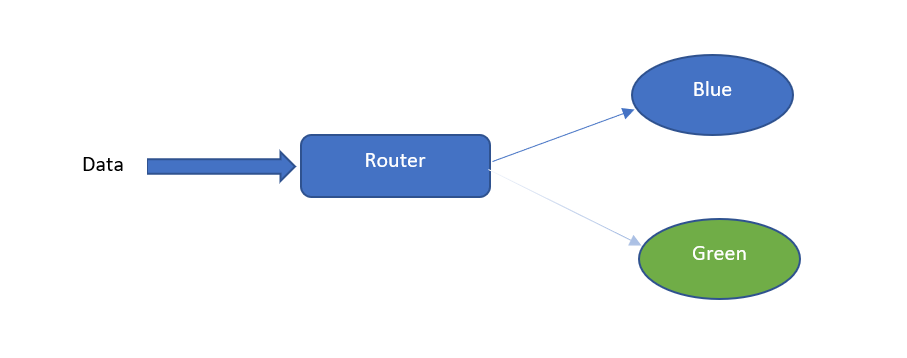
The traffic is gradually routed from the blue to the green environment. This ensures that downtime to users is minimum. It is very easy to roll back with this deployment strategy, as it is only a router switch. Read more on blue-green deployment here.
Conclusion
We hope you find this article helpful. However, we do not guarantee completeness or accuracy. Reader discretion is advised. Moreover, for benefit of our readers, here is a good article on Model Deployment Strategies.


