If Model Training is the science of Machine Learning, Feature Engineering is the art of it. Having said that, every work of art has some standard tips and tricks associated with it. Rather, we may say that there are first principles associated with it. While a Data Scientist may come up with some ingenious features, an ML engineer has to perform some standard data pre-processing/feature engineering steps like Feature Scaling, Vectorization etc.
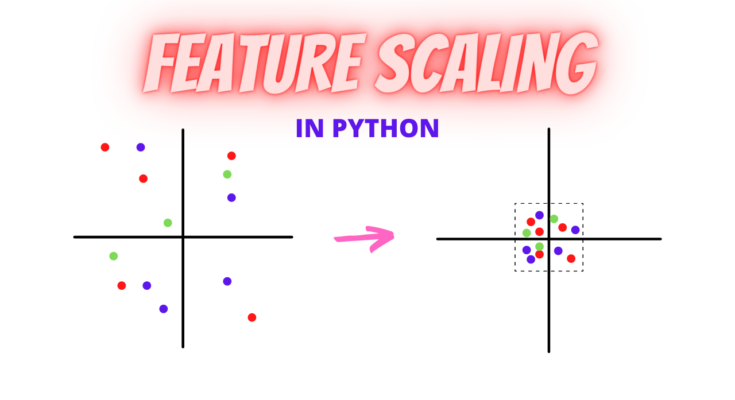
So why do need scaling? Most of the ML algorithms are sensitive to the order of magnitude of features. Thus, numerical features with higher order of magnitude adds more influence on the model predictions. Say for instance, in the california housing dataset, the number of bedrooms is way lower in order of magnitude, as compared to the population. Hence, we need to bring them into the same order of magnitude.
One way could be that we increase the order of magnitude of number of bedrooms. However, that makes it eat up more memory. Hence, standard practices suggest that all the numerical variables be squeezed into a smaller range. Moreover, the ML algorithms converge faster with smaller ranges.
Having said that, there are multiple ways of performing feature scaling. Below are a few of them:
- Rescaling (min-max normalization)
- Mean Normalization
- Standardization
- Scaling to unit length.
We won’t dive into the details of these techniques since, they have been covered beautifully in the wikipedia article on Feature Scaling. However, we will cover the practical aspects of scaling while training the ML Models.
Fortunately, libraries like Scikit learn have implemented most of the scaling techniques and we will use them to demonstrate feature scaling in real ML workflows.
Also read : Why is it good to do Feature Transforms for Deep Neural Networks?
Feature Scaling in Experimental Workflows
The first instance of feature scaling occurs in experiments. Typically, experimentation consists of feature discover and selection, data preprocessing, feature engineering, hyperparameter tuning and selection etc. This necessitates feature scaling. However, there is a simple nuance. While performing experiments, we typically split data into train, test and validation data sets. While doing so, the underlying assumption we carry is that the train, test and validation distributions are fairly similar.
In Applied ML, everything that is to be learnt, has to be learnt on the training data. Hence, we perform feature scaling first on training data and apply that on the test data. Now, what does that mean? Why not testing and validation data too? We do. But we need to understand that in scikit learn, the api’s that perform feature scaling essentially fits a model. Hence, similar to any ML model, the scaling model learns the properties of the numerical field from the training data and then applies the same to the validation and test data. We do this to prevent data leakage. Here is an example.
Let’s say, we have dataset with features X and label y. Here is the code for train test
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, stratify=y) X_train, X_cv, y_train, y_cv = train_test_split(X_train, y_train, test_size=0.30, stratify=y_train)
Further, let’s assume we have a column called price, that we wish to normalize. We use the scikit learn normalizer.
from sklearn.preprocessing import Normalizer normalizer = Normalizer() normalizer.fit(X_train['price'].values.reshape(-1,1)) #Note the fit function here X_train_price_norm = normalizer.transform(X_train['price'].values.reshape(1,-1)) #Transform validation and test data based on model learnt with training data X_cv_price_norm = normalizer.transform(X_cv['price'].values.reshape(1,-1)) X_test_price_norm = normalizer.transform(X_test['price'].values.reshape(1,-1)) X_train_price_norm = X_train_price_norm.reshape(-1,1) X_cv_price_norm = X_cv_price_norm.reshape(-1,1) X_test_price_norm = X_test_price_norm.reshape(-1,1)
Feature Scaling in Training Workflows
A training workflow does not consist of test and validation data (it does contain evaluation data). Moreover, to avoid training-serving skew, we need to train a model using a pipeline object, so that the features are transformed during serving. Thus, we use a scikit learn pipeline. Here is the example
X_train, X_test, y_train, y_test = train_test_split(x_df, y_df, test_size=0.2, random_state=0) #Train-Test Split
numerical = ['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup','Latitude','Longitude'] #List all Numerical Features
numeric_transformations = [([f], Pipeline(steps=[ ('imputer', SimpleImputer(strategy='median')), #Imputation and Scaling for all numerical variables.
('scaler', Normalizer())])) for f in numerical]
transformations = numeric_transformations
clf = Pipeline(steps=[('preprocessor', DataFrameMapper(transformations, df_out=True)), #Define the pipeline and its steps
('regressor', GradientBoostingRegressor())])
clf.fit(X_train, y_train) #Fit the Model
Note that there is not test dataset here. Hence, once the model is deployed, the serving dataset will go through the same transformations as the training dataset.
Conclusion
We hope this article is useful. Note that this is for information only and we do not claim any guarantees regarding it’s accuracy or completeness.
P.C. Analytics Vidya