Batch Inferencing with Azure ML is a complex affair. It entails creating a compute cluster, creating a parallel run step and running the batch inferencing pipeline. With small datasets, it is not a feasible option to set this up. Moreover, Managed Batch Endpoints are not yet mature enough. Hence, this article explores the option of using Managed Online Endpoints. Please note that this technique should be used only for smaller datasets (that can fit in Pandas Dataframe) or the data should be divided into mini-batches. Here, we will assume the former case.
Besides, we will use the same setup as our article on Managed Online Endpoints. We strongly recommend you to read our article on the same for step-by-step instructions on how to deploy a managed online endpoint. We won’t repeat the same and we will use the below deployed endpoint:

Step 0: Create Dataset for Batch Inferencing
Now, in order to perform Batch Inferencing, the first step is to create a Batch Data. We will use the California Housing Dataset, without the label column. But first, let’s create an Azure ML workspace object via the workspace config
from azureml.core import Workspace, Dataset, Datastore ws = Workspace.from_config()
Next, let’s create a folder for Batch Inferencing:
import os experiment_folder = 'California-Housing-Batch' os.mkdir(experiment_folder)
The following script creates a dataset for Inferencing. Note that there is no target column or label column.
import pandas as pd
from azureml.core import Dataset
from sklearn.datasets import fetch_california_housing
default_ds = ws.get_default_datastore()
if 'california dataset' not in ws.datasets:
# Register the tabular dataset
try:
california_housing = fetch_california_housing()
pd_df_california_housing = pd.DataFrame(california_housing.data, columns = california_housing.feature_names)
local_path = experiment_folder+'/california.csv'
pd_df_california_housing.to_csv(local_path, index = False)
datastore = ws.get_default_datastore()
# upload the local file from src_dir to the target_path in datastore
datastore.upload(src_dir=experiment_folder, target_path=experiment_folder, overwrite=True)
california_data_set = Dataset.Tabular.from_delimited_files(datastore.path(experiment_folder+'/california.csv'))
try:
california_data_set = california_data_set.register(workspace=ws, name='california dataset',
description='california data',
tags = {'format':'CSV'},
create_new_version=True)
print('Dataset registered.')
except Exception as ex:
print(ex)
print('Dataset registered.')
except Exception as ex:
print(ex)
else:
print('Dataset already registered.')
Step 1: Read Dataset for Batch
Next, read the California dataset and read it into a Pandas Dataframe:
dataset = Dataset.get_by_name(ws, name='california dataset') df_california_batch = dataset.to_pandas_dataframe()
Step 2: Prepare Dataset for Batch Inferencing
In the next step, prepare the data for Inferencing. This is a simple step where you convert the dataframe to a numpy array and create a JSON string out of it.
x = df_california_batch.to_numpy().tolist()
X = {'data': x}
Step 3: Score Data
Lastly, score the data using the below script:
import ssl
import json
import urllib
def allowSelfSignedHttps(allowed):
# bypass the server certificate verification on client side
if allowed and not os.environ.get('PYTHONHTTPSVERIFY', '') and getattr(ssl, '_create_unverified_context', None):
ssl._create_default_https_context = ssl._create_unverified_context
allowSelfSignedHttps(True) # this line is needed if you use self-signed certificate in your scoring service.
# Request data goes here
# The example below assumes JSON formatting which may be updated
# depending on the format your endpoint expects.
# More information can be found here:
# https://docs.microsoft.com/azure/machine-learning/how-to-deploy-advanced-entry-script
body = str.encode(json.dumps(X)) #create the body out of above JSON
url = 'https://california-housing-svr.<region>.inference.ml.azure.com/score'
api_key = '<your-api-key>' # Replace this with the API key for the web service
# The azureml-model-deployment header will force the request to go to a specific deployment.
# Remove this header to have the request observe the endpoint traffic rules
headers = {'Content-Type':'application/json', 'Authorization':('Bearer '+ api_key), 'azureml-model-deployment': 'default' }
req = urllib.request.Request(url, body, headers)
try:
response = urllib.request.urlopen(req)
result = response.read()
except urllib.error.HTTPError as error:
print("The request failed with status code: " + str(error.code))
# Print the headers - they include the requert ID and the timestamp, which are useful for debugging the failure
print(error.info())
print(error.read().decode("utf8", 'ignore'))
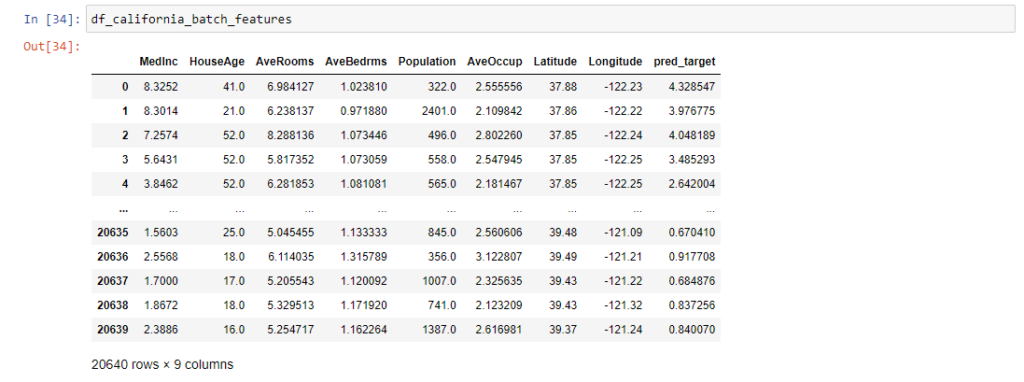
Finally, retrieve the predictions appended to the original feature Dataframe as shown below:
#Get Predictions pred_target=json.loads(result)['predictions'] #Append Predictions to the Features Dataframe df_california_batch_features['pred_target'] = pred_target