Evolution of Azure Synapse SQL
Azure Synapse was previously known as Azure SQL Datawarehouse. With the re-branding to Synapse, Microsoft added many more layers on top of it. The entire product or service is called Azure Synapse Analytics. Here is the Synapse architecture diagram from Microsoft:

Originally, Azure SQL DW was an SQL data warehousing as a service engine. But, Azure Synapse Analytics comprises two types of Analytics runtimes viz. SQL runtime and Apache Spark, along with other services like Integration services (Synapse Data Factory).
Also read : Migrate from ADF to Azure Synapse Integration.
Furthermore, the SQL runtime, i.e. Synapse SQL comes in two flavours:
- Dedicated SQL Pool
- Serverless SQL Pool
Dedicated SQL Pool
The dedicated SQL pool is the original SQL Datawarehouse. It is a distributed database/Data warehouse system powered by a massively parallel processing engine. As the name suggests, it is a dedicated SQL service, provisioned after creating the Azure Synapse Analytics workspace. A SQL server hosts the endpoint to the Data warehouse. Moreover, the scaling is under the control of users. The unit of scaling is Datawarehouse Unit (DWU). The architecture of the dedicated SQL pool is:
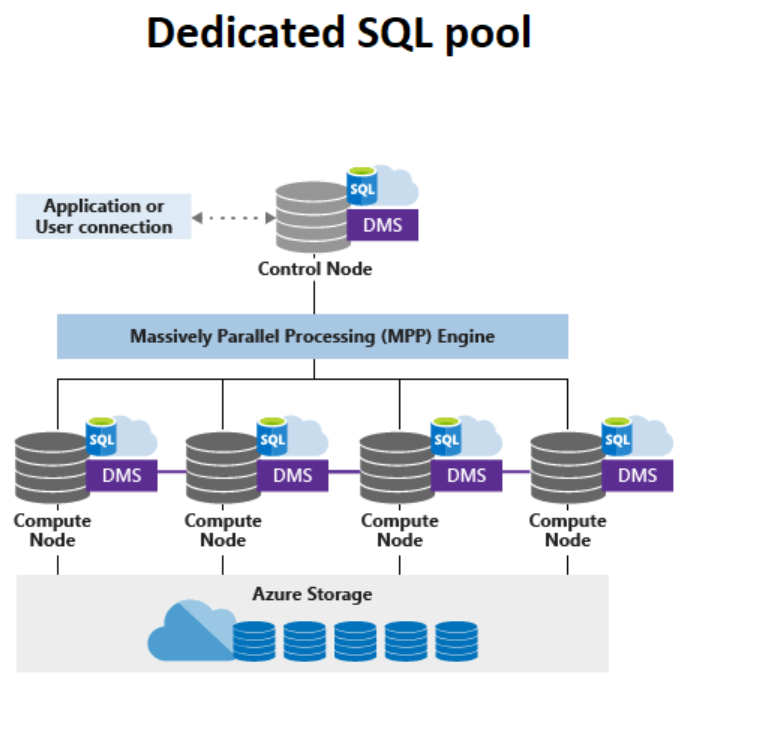
When a user runs an SQL statement, the control node distributes and orchestrates the query to compute nodes through the MPP engine. The user controls the amount of parallelism by tuning the Datawarehouse unit. More the DWU, more the parallelism and performance. This makes it suitable for complex analytical and reporting requirements.
To the end user, this service resembles a database. You can connect using tools like SSMS, create database objects like tables, views etc. Further, you can query the data and create reports on top of it, like any other database. However, there are certain additional features some limitations.
Additional features
- Distributed tables: The user can specify the distribution pattern.
- Polybase: This feature enables to query and load data from external data sources like blob storage and Azure Data Lake.
- CTAS/CETAS: Additional SQL constructs like Create Table As and Create External Table As to create distributed tables from existing data.
Limitations
- No cross database queries.
- No Foreign key constraints
- Unsupported SQL constructs: Computed columns, unique indexes, triggers, surrogate keys, etc. More details here.
Serverless SQL Pool
Dedicated SQL pool is suitable for the classical well-designed data warehousing system with complex analytical workloads. However, a lot of data exploration and analysis goes on before designing a data warehousing or data science workload. What if one wants to do a quickfire analysis on data lying in storage like blobs, data lakes or Cosmos db? You might be say that one can use Apache Spark pools. And rightly so. But can we have an SQL engine for the same, for data scientists and analysts? In Azure Synapse Analytics, the equivalent service is Serverless SQL Pool. Serverless pool, as the name suggests, is devoid of any infrastructure and comes by default with Azure Synapse Analytics.
Also read : Migrate Spark workloads from Azure Databricks to Azure Synapse.
Having said that, here is the architecture of serverless SQL pool.
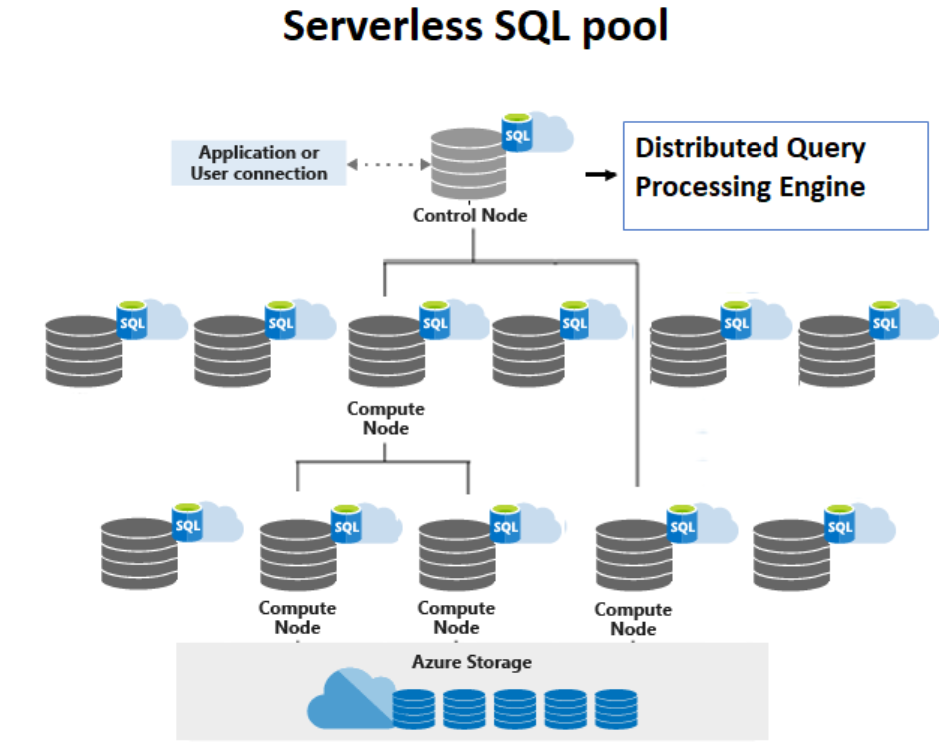
A control node uses the traditional distributed query processing engine of which MPP is a special case. As opposed to dedicated SQL pool, the scale out isn’t under the control of user.
Moreover, querying data using serverless pool differs from dedicated SQL pool. Though it offers T-SQL like constructs, it cannot create SQL tables. Instead, we can create views and external tables on top of data stored in various sources. Please note, this is an engine for analytics and not for data manipulation. You know read more about it here.
Conclusion
This is an introductory article on Azure Synapse SQL. Please note that this is only for information only. Hence, we do not claim any guarantees regarding its accuracy or completeness.
Notes
- We wrote our first blog on Synapse, on the same day as the Azure Synapse was launched. Read this article to know more: Azure Synapse Analytics: Azure SQL Data Warehouse revamped.
- Lastly, on serverless SQL pool, we have a similar concept in Databricks i.e. Delta Engine and Databricks SQL. Read this article to know more: Motivating Databricks Delta in Azure.